Memory-Efficient LLM Inference via MoH-Guided Head-wise Offloading (In Progress)
Routing trace analysis -> head importance & regularity -> offloading/prefetch strategies -> accuracy/performance trade-off validation
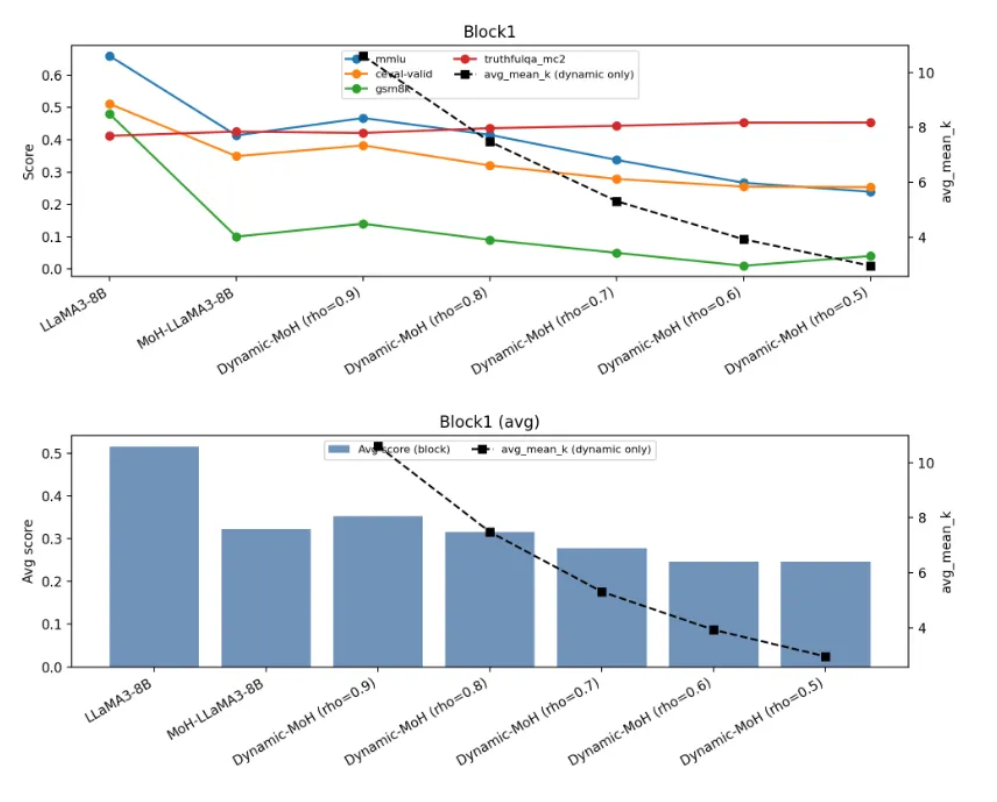
Overview
Key contributions
System Architecture
Bring-up Pipeline
Validation & Evidence
Debugging Case Study
Symptom:
Hypotheses:
Tests:
Fix:
Takeaway: